TF-IDF metin madenciliği yani text mining olarak geçmekte olan ve data mining yani veri madenciliği natural language processing yani doğal dil işleme konularının ortak şekilde üzerinde çalıştığı metinler için istatistiki inceleme alanında kullanılır. TF-IDF sıralama yani ranking algoritmasıdır. Information retvial (bilgi getirimi) konuların altında sıkça geçer.
TF-IDF Hangi Amaçla Kullanılır?
TF-IDF kavramının hangi alanda kullanıldığını incelemeden önce kelimenin anlamını anlamakta fayda vardır. TF-IDF kavramı ters metin frekansı ve Terim frekansı kelimelerini temsil eder. İngilizceleri olan Term frequeny ve inverse document frequeny kelimelerinin baş harflerinden oluşmuştur. Basit olarak TF-IDF terimlerin kullanım sıklığı üzerine hesap yapan bir algoritmadır.
Klasik bir şekilde TF terimlerin kaç defa kullanıldığını hesaplamaktan daha iyi sonuçlar sağlamaktadır. TF-IDF hesabı kritik iki sayıdan oluşmaktadır. Birinci sayı anlık olarak kullanımda olan dokümanın sahip olduğu terim sayısı bir diğeri de bu terimi içeriğinde bulunduran dokümanların sayısıdır.
TF-IDF Nasıl Hesaplanır?
TF-IDF’nin çalışma prensibi bir örnek üzerinden daha iyi anlaşılacaktır.
Örnek üzerinde 200 dokümana sahip bir külliyat olduğunu varsayalım. TF-IDF üzerinden sayısı hesaplanmak istenen kelimeyi de “okul” olarak belirlemiş olalım. Bu şartlarda birinci doküman incelenip kaç adet “okul” kelimesi geçtiği sayılır. Örnekte bu sayı 5 bulunmuş olsun. Bu sayının bulunmasının ardından toplamdaki 200 dokümanda kaç adet “okul” kelimesi geçiyor diye bakılır. Örneğimizde başka 20 dokümanda da bu kelime geçiyor olsun. Dikkat edilmesi gereken husus diğer dokümanlarda kaç adet geçtiği değildir, diğer dokümanlarda okul kelimesinin geçip geçmediğidir. Bir sonraki adımda TF ve IDF değerleri ayrı ayrı hesaplanacak ve bu iki değer çarpılacaktır.
Öncelikle IDF değeri nasıl hesaplanır onu inceleyelim. IDF değeri için temel bir bölme işlemi yapılmalı ve logaritması alınmalıdır.
IDF bulunurken toplam doküman sayısı terimi içermekte olan doküman sayısına bölünür. Şu şekilde formüle edilebilir:
IDF= log(Toplam doküman sayısı ÷ terimi içermekte olan doküman sayısı)
IDF hesabı yapmak için örneğe geri döndüğümüzde toplam 200 dokümandan 20 dokümanda “okul” kelimesinin geçtiği belirlenmişti. Formüle uygulandığında:
IDF= log(200÷20) = log(10) = 1 olarak çıkmaktadır.
IDF hesaplaması yapılırken dikkat edilmesi gereken 2 önemli nokta vardır:
- IDF hesabı yapılırken terimi içeren doküman sayısına dikkat edilmelidir. Çünkü bu değer 0 olarak bulunabilir yani terimi içeren doküman olmayabilir. Terimi içeren doküman sayısı paydada bulunduğu için formüle 0 olarak aktarıldığında, paydadaki sıfır belirsizlik yaratacağı için sonuç belirsiz olacaktır. Bu sebeple programlamacılar genellikle sonuç sıfır çıktığı zaman 1 sayı ekleyerek paydayı belirsizlikten kurtarırlar. Böyle bir durumla karşılaşıldığında işlem 1 ekleyerek gerçekleştirilmelidir.
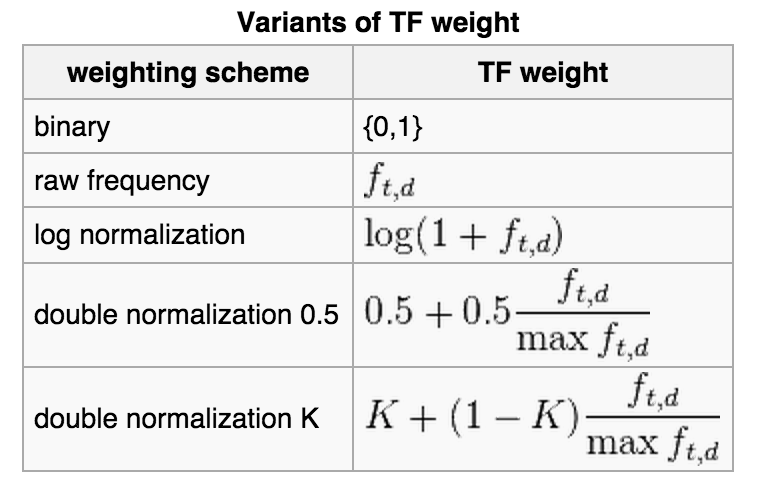
IDF hesabı yapılırken hesaplamada kullanılan logaritmanın hangi tabanda olduğunun bir önemi bulunmamaktadır. İşlemin amacı üslü sayı fonksiyonunun tersine bir işlem gerçekleştirmektir. Normalde logaritma kökü 2,e ya da 10 gibi sayılar olarak kullanılır. Çoğunlukla TF-IDF değerleri kıyaslama amacıyla kullanılır. Bu sebeple de hepsinde aynı tabanın kullanılması sonuç için bir değişiklik yaratmayacaktır.
TF hesabı yapılırken ihtiyaç duyulan değer o an dokümanda en fazla sayıda geçmekte olan terimin sayısıdır. Örneğimizde o an bakılan dokümanda en fazla geçen terim sayısını 50 kabul edelim.
TF hesabı o an dokümanda ilgilendiğimiz kelimenin yani “okul” kelimesinin en fazla geçen kelimeye oranıdır. Kelimemiz de 5 kere kullanılmıştı. Böylece ilk oran yani terim frekansı (TF), 5 ÷50 şeklinde hesaplanacaktır. Bu işlemin sonucu da 0,10 olarak bulunacaktır.
Sonuç olarak TF değeri 0,10 ve IDF değeri 1 olarak bulunmuş oluyor. Başlangıçta belirtildiği gibi TF-IDF değeri bu iki değerin çarpılmasıyla bulunmaktadır. Yani örneğimiz için TF-IDF= 0,1 olarak bulunacaktır.















{kind=link}